) играет осо-бо важную роль в теории вероятностей и чаще других применяется в решении практических задач. Его главная особенность в том, что он является предельным законом, к которому приближаются дру-гие законы распределения при весьма часто встречающихся типич-ных условиях. Например, сумма достаточно большого числа неза-висимых (или слабо зависимых) случайных величин приближенно подчиняется нормальному закону, и это выполняется тем точнее, чем больше случайных величин суммируется.
Экспериментально доказано, что нормальному закону под-чиняются погрешности измерений, отклонения геометрических размеров и положения элементов строительных конструкций при их изготовлении и монтаже, изменчивость физико-механических характеристик материалов и нагру-зок, действующих на строительные конструкции.
Распределению Гаусса подчи-няются почти все случайные вели-чины, отклонение которых от сред-них значений вызывается большой совокупностью случайных факто-ров, каждый из которых в отдельности незначителен (центральная предельная теорема).
Нормальным распределением называется распределение случайной непрерывной величины, для которых плотность вероят-ностей имеет вид (рис. 18.1).
Рис. 18.1. Нормальный закон распределения при а 1 < a 2 .
| (18.1) |
где а и — параметры распределения.
Вероятностные характеристики случайной величины, распре-деленной по нормальному закону, равны:
Математическое ожидание (18.2)
Дисперсия (18.3)
Среднеквадратичное отклонение (18.4)
Коэффициент асимметрии А = 0 (18.5)
Эксцесс Е = 0. (18.6)
Параметр σ, входящий в распределение Гаусса равен сред-неквадратичному отношению слу-чайной величины. Величина а оп-ределяет положение центра рас-пределения (см. рис. 18.1), а величина а — ширину распределе-ния (рис. 18.2), т.е. статистический разброс вокруг средней величины.
Рис. 18.2. Нормальный закон распределения при σ 1 < σ 2 < σ 3
Вероятность попадания в заданный интервал (от x 1 до x 2) для нормального распределения, как и во всех случаях, определяется интегралом от плотности вероятности (18.1), который не выража-ется через элементарные функции и представляется специальной функцией, называется функцией Лапласа (интеграл вероятностей).
Одно из представлений интеграла вероятностей:
Величина и называется квантилем.
Видно, что Ф(х) — нечетная функция, т. е. Ф(-х) = -Ф(х). Значения этой функции вычислены и представлены в виде таблиц в технической и учебной литературе.
Функция распределения нормального закона (рис. 18.3) может быть выражена через ин-теграл вероятностей:
Рис. 18.2. Функция нормального закона распределения.
Вероятность попадания случайной величины, распределенной по нормальному закону, в интервал от х. до х, определяется выра-жением:
Следует заметить, что
Ф(0) = 0; Ф(∞) = 0,5; Ф(-∞) = -0,5.
При решении практических задач, связанных с распределе-нием, часто приходится рассматривать вероятность попадания в интервал, симметричный относительно математического ожидания, если длина этого интервала т.е. если сам интервал имеет грани-цу от до , имеем:
При решении практических задач границы отклонений слу-чайных величин выражаются через стандарт, среднеквадратичное отклонение, умноженное на некоторый множитель, определяющий границы области отклонений случайной величины.
Принимая и а также используя формулу (18.10) и таблицу Ф(х) (приложение № 1), получим
Эти формулы показывают , что если случайная величина име-ет нормальное распределение, то вероятность ее отклонения от сво-его среднего значения не более чем на σ составляет 68,27 %, не бо-лее чем на 2σ — 95,45 % и не более чем на Зσ — 99,73 %.
Поскольку величина 0,9973 близка к единице, практически считается невозможным отклонение нормального распределения случайной величины от математического ожидания более чем на Зσ. Это правило, справедливое только для нормального распределения, называется правилом трех сигм. Нарушение его имеет вероятность Р = 1 - 0,9973 = 0,0027. Этим правилом пользуются при установле-нии границ допустимых отклонений допусков геометрических ха-рактеристик изделий и конструкций.
Нормальное распределение (normal distribution ) - играет важную роль в анализе данных.
Иногда вместо термина нормальное распределение употребляют термин гауссовское распределение в честь К. Гаусса (более старые термины, практически не употребляемые в настоящее время: закон Гаусса, Гаусса-Лапласа распределение).
Одномерное нормальное распределение
Нормальное распределение имеет плотность::
В этой формуле , фиксированные параметры, - среднее , - стандартное отклонение .
Графики плотности при различных параметрах приведены .
Характеристическая функция нормального распределения имеет вид:
![]()
Дифференцируя характеристическую функцию и полагая t = 0 , получаем моменты любого порядка.
Кривая плотности нормального распределения симметрична относительно и имеет в этой точке единственный максимум, равный
Параметр стандартного отклонения меняется в пределах от 0 до ∞.
Среднее меняется в пределах от -∞ до +∞.
При увеличении параметра кривая растекается вдоль оси х , при стремлении к 0 сжимается вокруг среднего значения (параметр характеризует разброс, рассеяние).
При изменении кривая сдвигается вдоль оси х (см. графики).
Варьируя параметры и , мы получаем разнообразные модели случайных величин, возникающие в телефонии.
Типичное применение нормального закона в анализе, например, телекоммуникационных данных - моделирование сигналов, описание шумов, помех, ошибок, трафика.
Графики одномерного нормального распределения

Рисунок 1. График плотности нормального распределения: среднее равно 0, стандартное отклонение 1

Рисунок 2. График плотности стандартного нормального распределения с областями, содержащими 68% и 95% всех наблюдений

Рисунок 3. Графики плотностей нормальных распределений c нулевым средним и разными отклонениями (=0.5, =1, =2)

Рисунок 4 Графики двух нормальных распределений N(-2,2) и N(3,2).
Заметьте, центр распределения сдвинулся при изменении параметра .
Замечание
В программе STATISTICA под обозначением N(3,2) понимается нормальный или гауссов закон с параметрами: среднее = 3 и стандартное отклонение =2.
В литературе иногда второй параметр трактуется как дисперсия , т.е. квадрат стандартного отклонения.
Вычисления процентных точек нормального распределения с помощью вероятностного калькулятора STATISTICA
С помощью вероятностного калькулятора STATISTICA можно вычислить различные характеристики распределений, не прибегая к громоздким таблицам, используемым в старых книгах.
Шаг 1. Запускаем Анализ / Вероятностный калькулятор / Распределения .
В разделе распределения выберем нормальное .

Рисунок 5. Запуск калькулятора вероятностных распределений
Шаг 2. Указываем интересующие нас параметры.
Например, мы хотим вычислить 95% квантиль нормального распределения со средним 0 и стандартным отклонением 1.
Укажем эти параметры в полях калькулятора (см. поля калькулятора среднее и стандартное отклонение).
Введем параметр p=0,95.
Галочка «Обратная ф.р». отобразится автоматически. Поставим галочку «График».
Нажмем кнопку «Вычислить» в правом верхнем углу.

Рисунок 6. Настройка параметров
Шаг 3. В поле Z получаем результат: значение квантиля равно 1,64 (см. следующее окно).

Рисунок 7. Просмотр результата работы калькулятора

Рисунок 8. Графики плотности и функции распределения. Прямая x=1,644485




Рисунок 9. Графики функции нормального распределения. Вертикальные пунктирные прямые- x=-1.5, x=-1, x=-0.5, x=0


Рисунок 10. Графики функции нормального распределения. Вертикальные пунктирные прямые- x=0.5, x=1, x=1.5, x=2
Оценка параметров нормального распределения
Значения нормального распределения можно вычислить с помощью интерактивного калькулятора .
Двумерное нормальное распределение
Одномерное нормальное распределение естественно обобщается на двумерное нормальное распределение.
Например, если вы рассматриваете сигнал только в одной точке, то вам достаточно одномерного распределения, в двух точках - двумерного, в трех точках - трехмерного и т.д.
Общая формула для двумерного нормального распределения имеет вид:

Где - парная корреляция между X 1 и X 2 ;
X 1 соответственно;
Среднее и стандартное отклонение переменной X 2 соответственно.
Если случайные величины Х 1 и Х 2 независимы, то корреляция равна 0, = 0, соответственно средний член в экспоненте зануляется, и мы имеем:
f(x 1 ,x 2) = f(x 1)*f(x 2)
Для независимых величин двумерная плотность распадается в произведение двух одномерных плотностей.
Графики плотности двумерного нормального распределения

Рисунок 11. График плотности двумерного нормального распределения (нулевой вектор средних, единичная ковариационная матрица)

Рисунок 12. Сечение графика плотности двумерного нормального распределения плоскостью z=0.05

Рисунок 13. График плотности двумерного нормального распределения (нулевой вектор мат. ожидания, ковариационная матрица с 1 на главной диагонали и 0.5 на побочной)

Рисунок 14. Сечение графика плотности двумерного нормального распределения (нулевой вектор мат. ожидания, ковариационная матрица с 1 на главной диагонали и 0.5 на побочной) плоскостью z= 0.05

Рисунок 15. График плотности двумерного нормального распределения (нулевой вектор мат. ожидания, ковариационная матрица с 1 на главной диагонали и -0.5 на побочной)

Рисунок 16. Сечение графика плотности двумерного нормального распределения (нулевой вектор мат. ожидания, ковариационная матрица с 1 на главной диагонали и -0.5 на побочной) плоскостью z=0.05

Рисунок 17. Сечения графиков плотностей двумерного нормального распределения плоскостью z=0.05
Для лучшего понимания двумерного нормального распределения попробуйте решить следующую задачу.
Задача. Посмотрите на график двумерного нормального распределения. Подумайте, можно ли его представить, как вращение графика одномерного нормального распределения? Когда нужно применить прием деформации?
В теории вероятностей рассматривается достаточно большое количество разнообразных законов распределения. Для решения задач, связанных с построением контрольных карт, представляют интерес лишь некоторые из них. Важнейшим из них является нормальный закон распределения , который применяется для построения контрольных карт, используемых при контроле по количественному признаку , т.е. когда мы имеем дело с непрерывной случайной величиной. Нормальный закон распределения занимает среди других законов распределения особое положение. Это объясняется тем, что, во-первых, наиболее часто встречается на практике, и, во-вторых, он является предельным законом, к которому приближаются другие законы распределения при весьма часто встречающихся типичных условиях. Что касается второго обстоятельства, то в теории вероятностей доказано, что сумма достаточно большого числа независимых (или слабо зависимых) случайных величин, подчиненных каким угодно законам распределения (при соблюдении некоторых весьма нежестких ограничений), приближенно подчиняется нормальному закону, и это выполняется тем точнее, чем большее количество случайных величин суммируется. Большинство встречающихся на практике случайных величин, таких, например, как ошибки измерений, могут быть представлены как сумма весьма большего числа сравнительно малых слагаемых - элементарных ошибок, каждая из которых вызвана действием отдельной причины, независящей от остальных. Нормальный закон проявляется в тех случаях, когда случайная переменная Х является результатом действия большого числа различных факторов. Каждый фактор в отдельности на величину Х влияет незначительно, и нельзя указать, какой именно влияет в большей степени, чем остальные.
Нормальное распределение (распределение Лапласа–Гаусса ) – распределение вероятностей непрерывной случайной величины Х такое, что плотность распределения вероятностей при - ¥ <х< + ¥ принимает действительное значение:
Ехр  (3)
(3)
То есть, нормальное распределение характеризуется двумя параметрами m и s, где m - математическое ожидание; s- стандартное отклонение нормального распределения.
Величина s 2 – это дисперсия нормального распределения.
Математическое ожидание m характеризует положение центра распределения, а стандартное отклонение s (СКО) является характеристикой рассеивания (рис. 3).
f(x) f(x)
 |
Рисунок 3 – Функции плотности нормального распределения с:
а) разными математическими ожиданиями m; б) разными СКО s .
Таким образом, значением μ определяется положением кривой распределения на оси абсцисс. Размерность μ - та же, что и размерность случайной величины X . С ростом математического ожидания mобе функции сдвигается параллельно вправо. С убывающей дисперсией s 2 плотность все больше концентрируется вокруг m, в то время как функция распределения становится все более крутой.
Значением σ определяется форма кривой распределения. Поскольку площадь под кривой распределения должна всегда оставаться равной единице, то при увеличении σ кривая распределения становится более плоской. На рис. 3.1 показаны три кривые при разных σ: σ1 = 0,5; σ2 = 1,0; σ3 = 2,0.

Рисунок 3.1 – Функции плотности нормального распределения с разными СКО s .
Функция распределения (интегральная функция) имеет вид (рис. 4):

 (4)
(4)
Рисунок 4 – Интегральная (а) и дифференциальная (б) функции нормального распределения
Особенно важно то линейное преобразование нормально распределенной случайной переменной Х , после которого получается случайная переменная Z с математическим ожиданием 0 и дисперсией 1. Такое преобразование называется нормированием:
Его можно провести для каждой случайной переменной. Нормирование позволяет все возможные варианты нормального распределения свести к одному случаю: m = 0, s = 1.
Нормальное распределение с m = 0, s = 1 называется нормированным нормальным распределением (стандартизованным) .
Стандартное нормальное распределение (стандартное распределение Лапласа–Гаусса или нормированное нормальное распределение) – это распределение вероятностей стандартизованной нормальной случайной величины Z , плотность распределения которой равна:
при - ¥ <z < + ¥
Значения функции Ф(z) определяется по формуле:
 (7)
(7)
Значения функции Ф(z) и плотности ф(z) нормированного нормального распределения рассчитаны и сведены в таблицы (табулированы). Таблица составлена только для положительных значений z поэтому:
Ф (–z) = 1 –Ф (z) (8)
С помощью этих таблиц можно определить не только значения функции и плотности нормированного нормального распределения для заданного z , но и значения функции общего нормального распределения, так как:
![]() ; (9)
; (9)
![]() . 10)
. 10)
Во многих задачах, связанных с нормально распределенными случайными величинами, приходится определять вероятность попадания случайной величины Х , подчиненной нормальному закону с параметрами m и s, на определенный участок. Таким участком может быть, например, поле допуска на параметр от верхнего значения U до нижнего L .
Вероятность попадания в интервал от х 1 до х 2 можно определить по формуле:
Таким образом, вероятность попадания случайной величины (значение параметра) Х в поле допуска определяется формулой
Примерами случайных величин, распределённых по нормальному закону, являются рост человека, масса вылавливаемой рыбы одного вида . Нормальность распределения означает следующее : существуют значения роста человека, массы рыбы одного вида, которые на интуитивном уровне воспринимаются как "нормальные" (а по сути - усреднённые), и они-то в достаточно большой выборке встречаются гораздо чаще, чем отличающиеся в бОльшую или меньшую сторону.
Нормальное распределение вероятностей непрерывной случайной величины (иногда - распределение Гаусса) можно назвать колоколообразным из-за того, что симметричная относительно среднего функция плотности этого распределения очень похожа на разрез колокола (красная кривая на рисунке выше).
Вероятность встретить в выборке те или иные значение равна площади фигуры под кривой и в случае нормального распределения мы видим, что под верхом "колокола", которому соответствуют значения, стремящиеся к среднему, площадь, а значит, вероятность, больше, чем под краями. Таким образом, получаем то же, что уже сказано: вероятность встретить человека "нормального" роста, поймать рыбу "нормальной" массы выше, чем для значений, отличающихся в бОльшую или меньшую сторону. В очень многих случаях практики ошибки измерения распределяются по закону, близкому к нормальному.
Остановимся ещё раз на рисунке в начале урока, на котором представлена функция плотности нормального распределения. График этой функции получен при рассчёте некоторой выборки данных в пакете программных средств STATISTICA . На ней столбцы гистограммы представляют собой интервалы значений выборки, распределение которых близко (или, как принято говорить в статистике, незначимо отличаются от) к собственно графику функции плотности нормального распределения, который представляет собой кривую красного цвета. На графике видно, что эта кривая действительно колоколообразная.
Нормальное распределение во многом ценно благодаря тому, что зная только математическое ожидание непрерывной случайной величины и стандартное отклонение, можно вычислить любую вероятность, связанную с этой величиной.
Нормальное распределение имеет ещё и то преимущество, что один из наиболее простых в использовании статистических критериев, используемых для проверки статистических гипотез - критерий Стьюдента - может быть использован только в том случае, когда данные выборки подчиняются нормальному закону распределения.
Функцию плотности нормального распределения непрерывной случайной величины можно найти по формуле:
 ,
,
где x - значение изменяющейся величины, - среднее значение, - стандартное отклонение, e =2,71828... - основание натурального логарифма, =3,1416...
Свойства функции плотности нормального распределения
Изменения среднего значения перемещают кривую функции плотности нормального распределения в направлении оси Ox . Если возрастает, кривая перемещается вправо, если уменьшается, то влево.
Если меняется стандартное отклонение, то меняется высота вершины кривой. При увеличении стандартного отклонения вершина кривой находится выше, при уменьшении - ниже.
Вероятность попадания значения нормально распределённой случайной величины в заданный интервал
Уже в этом параграфе начнём решать практические задачи, смысл которых обозначен в заголовке. Разберём, какие возможности для решения задач предоставляет теория. Отправное понятие для вычисления вероятности попадания нормально распределённой случайной величины в заданный интервал - интегральная функция нормального распределения.
Интегральная функция нормального распределения :
 .
.
Однако проблематично получить таблицы для каждой возможной комбинации среднего и стандартного отклонения. Поэтому одним из простых способов вычисления вероятности попадания нормально распределённой случайной величины в заданный интервал является использование таблиц вероятностей для стандартизированного нормального распределения.
Стандартизованным или нормированным называется нормальное распределение , среднее значение которого , а стандартное отклонение .
Функция плотности стандартизованного нормального распределения :
![]() .
.
Интегральная функция стандартизованного нормального распределения :
 .
.
На рисунке ниже представлена интегральная функция стандартизованного нормального распределения, график которой получен при рассчёте некоторой выборки данных в пакете программных средств STATISTICA . Собственно график представляет собой кривую красного цвета, а значения выборки приближаются к нему.

Для увеличения рисунка можно щёлкнуть по нему левой кнопкой мыши.
Стандартизация случайной величины означает переход от первоначальных единиц, используемых в задании, к стандартизованным единицам. Стандартизация выполняется по формуле
На практике все возможные значения случайной величины часто не известны, поэтому значения среднего и стандартного отклонения точно определить нельзя. Их заменяют средним арифметическим наблюдений и стандартным отклонением s . Величина z выражает отклонения значений случайной величины от среднего арифметического при измерении стандартных отклонений.
Открытый интервал
Таблица вероятностей для стандартизированного нормального распределения, которая есть практически в любой книге по статистике, содержит вероятности того, что имеющая стандартное нормальное распределение случайная величина Z примет значение меньше некоторого числа z . То есть попадёт в открытый интервал от минус бесконечности до z . Например, вероятность того, что величина Z меньше 1,5, равна 0,93319.
Пример 1. Предприятие производит детали, срок службы которых нормально распределён со средним значением 1000 и стандартным отклонением 200 часов.
Для случайно отобранной детали вычислить вероятность того, что её срок службы будет не менее 900 часов.
Решение. Введём первое обозначение:
Искомая вероятность.
Значения случайной величины находятся в открытом интервале. Но мы умеем вычислять вероятность того, что случайная величина примет значение, меньшее заданного, а по условию задачи требуется найти равное или большее заданного. Это другая часть пространства под кривой плотности нормального распределения (колокола). Поэтому, чтобы найти искомую вероятность, нужно из единицы вычесть упомянутую вероятность того, что случайная величина примет значение, меньше заданного 900:
Теперь случайную величину нужно стандартизировать.
Продолжаем вводить обозначения:
z = (X ≤ 900) ;
x = 900 - заданное значение случайной величины;
μ = 1000 - среднее значение;
σ = 200 - стандартное отклонение.
По этим данным условия задачи получаем:
![]() .
.
По таблицам стандартизированной случайной величине (границе интервала) z = −0,5 соответствует вероятность 0,30854. Вычтем ее из единицы и получим то, что требуется в условии задачи:
Итак, вероятность того, что срок службы детали будет не менее 900 часов, составляет 69%.
Эту вероятность можно получить, используя функцию MS Excel НОРМ.РАСП (значение интегральной величины - 1):
P (X ≥900) = 1 - P (X ≤900) = 1 - НОРМ.РАСП(900; 1000; 200; 1) = 1 - 0,3085 = 0,6915.
О расчётах в MS Excel - в одном из последующих параграфах этого урока.
Пример 2. В некотором городе среднегодовой доход семьи является нормально распределённой случайной величиной со средним значением 300000 и стандартным отклонением 50000. Известно, что доходы 40 % семей меньше величины A . Найти величину A .
Решение. В этой задаче 40 % - ни что иное, как вероятность того, что случайная величина примет значение из открытого интервала, меньшее определённого значения, обозначенного буквой A .
Чтобы найти величину A , сначала составим интегральную функцию:
![]()
По условию задачи
μ = 300000 - среднее значение;
σ = 50000 - стандартное отклонение;
x = A - величина, которую нужно найти.
Составляем равенство
![]() .
.
По статистическим таблицам находим, что вероятность 0,40 соответствует значению границы интервала z = −0,25 .
Поэтому составляем равенство
![]()
и находим его решение:
A = 287300 .
Ответ: доходы 40 % семей менее 287300.
Закрытый интервал
Во многих задачах требуется найти вероятность того, что нормально распределённая случайная величина примет значение в интервале от z 1 до z 2 . То есть попадёт в закрытый интервал. Для решения таких задач необходимо найти в таблице вероятности, соответствующие границам интервала, а затем найти разность этих вероятностей. При этом требуется вычитать меньшее значение из большего. Примеры на решения этих распространённых задач - следующие, причём решить их предлагается самостоятельно, а затем можно посмотреть правильные решения и ответы.
Пример 3. Прибыль предприятия за некоторый период - случайная величина, подчинённая нормальному закону распределения со средним значением 0,5 млн. у.е. и стандартным отклонением 0,354. Определить с точностью до двух знаков после запятой вероятность того, что прибыль предприятия составит от 0,4 до 0,6 у.е.
Пример 4. Длина изготавливаемой детали представляет собой случайную величину, распределённую по нормальному закону с параметрами μ =10 и σ =0,071 . Найти с точностью до двух знаков после запятой вероятность брака, если допустимые размеры детали должны быть 10±0,05 .
Подсказка: в этой задаче помимо нахождения вероятности попадания случайной величины в закрытый интервал (вероятность получения небракованной детали) требуется выполнить ещё одно действие.
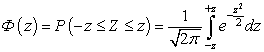
позволяет определить вероятность того, что стандартизованное значение Z не меньше -z и не больше +z , где z - произвольно выбранное значение стандартизованной случайной величины.
Приближенный метод проверки нормальности распределения
Приближенный метод проверки нормальности распределения значений выборки основан на следующем свойстве нормального распределения: коэффициент асимметрии β 1 и коэффициент эксцесса β 2 равны нулю .
Коэффициент асимметрии β 1 численно характеризует симметрию эмпирического распределения относительно среднего. Если коэффициент асимметрии равен нулю, то среднее арифметрического значение, медиана и мода равны: и кривая плотности распределения симметрична относительно среднего. Если коэффициент асимметрии меньше нуля (β 1 < 0 ), то среднее арифметическое меньше медианы, а медиана, в свою очередь, меньше моды () и кривая сдвинута вправо (по сравнению с нормальным распределением) . Если коэффициент асимметрии больше нуля (β 1 > 0 ), то среднее арифметическое больше медианы, а медиана, в свою очередь, больше моды () и кривая сдвинута влево (по сравнению с нормальным распределением) .
Коэффициент эксцесса β 2 характеризует концентрацию эмпирического распределения вокруг арифметического среднего в направлении оси Oy и степень островершинности кривой плотности распределения. Если коэффициент эксцесса больше нуля, то кривая более вытянута (по сравнению с нормальным распределением) вдоль оси Oy (график более островершинный). Если коэффициент эксцесса меньше нуля, то кривая более сплющена (по сравнению с нормальным распределением) вдоль оси Oy (график более туповершинный).
Коэффициент асимметрии можно вычислить с помощью функции MS Excel СКОС. Если вы проверяете один массив данных, то требуется ввести диапазон данных в одно окошко "Число".

Коэффициент эксцесса можно вычислить с помощью функции MS Excel ЭКСЦЕСС. При проверке одного массива данных также достаточно ввести диапазон данных в одно окошко "Число".

Итак, как мы уже знаем, при нормальном распределении коэффициенты асимметрии и эксцесса равны нулю. Но что, если мы получили коэффициенты асимметрии, равные -0,14, 0,22, 0,43, а коэффициенты эксцесса, равные 0,17, -0,31, 0,55? Вопрос вполне справедливый, так как практически мы имеем дело лишь с приближенными, выборочными значениями асимметрии и эксцесса, которые подвержены некоторому неизбежному, неконтролируемому разбросу. Поэтому нельзя требовать строгого равенства этих коэффициентов нулю, они должны лишь быть достаточно близкими к нулю. Но что значит - достаточно?
Требуется сравнить полученные эмпирические значения с допустимыми значениями. Для этого нужно проверить следующие неравенства (сравнить значения коэффициентов по модулю с критическими значениями - границами области проверки гипотезы).
Для коэффициента асимметрии β 1 .
На практике большинство случайных величин, на которых воздействует большое количество случайных факторов, подчиняются нормальному закону распределения вероятностей. Поэтому в различных приложениях теории вероятностей этот закон имеет особое значение.
Случайная величина $X$ подчиняется нормальному закону распределения вероятностей, если ее плотность распределения вероятностей имеет следующий вид
$$f\left(x\right)={{1}\over {\sigma \sqrt{2\pi }}}e^{-{{{\left(x-a\right)}^2}\over {2{\sigma }^2}}}$$
Схематически график функции $f\left(x\right)$ представлен на рисунке и имеет название «Гауссова кривая». Справа от этого графика изображена банкнота в 10 марок ФРГ, которая использовалась еще до появления евро. Если хорошо приглядеться, то на этой банкноте можно заметить гауссову кривую и ее первооткрывателя величайшего математика Карла Фридриха Гаусса.
Вернемся к нашей функции плотности $f\left(x\right)$ и дадим кое-какие пояснения относительно параметров распределения $a,\ {\sigma }^2$. Параметр $a$ характеризует центр рассеивания значений случайной величины, то есть имеет смысл математического ожидания. При изменении параметра $a$ и неизмененном параметре ${\sigma }^2$ мы можем наблюдать смещение графика функции $f\left(x\right)$ вдоль оси абсцисс, при этом сам график плотности не меняет своей формы.

Параметр ${\sigma }^2$ является дисперсией и характеризует форму кривой графика плотности $f\left(x\right)$. При изменении параметра ${\sigma }^2$ при неизмененном параметре $a$ мы можем наблюдать, как график плотности меняет свою форму, сжимаясь или растягиваясь, при этом не сдвигаясь вдоль оси абсцисс.

Вероятность попадания нормально распределенной случайной величины в заданный интервал
Как известно, вероятность попадания случайной величины $X$ в интервал $\left(\alpha ;\ \beta \right)$ можно вычислять $P\left(\alpha < X < \beta \right)=\int^{\beta }_{\alpha }{f\left(x\right)dx}$. Для нормального распределения случайной величины $X$ с параметрами $a,\ \sigma $ справедлива следующая формула:
$$P\left(\alpha < X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right)$$
Здесь функция $\Phi \left(x\right)={{1}\over {\sqrt{2\pi }}}\int^x_0{e^{-t^2/2}dt}$ - функция Лапласа. Значения этой функции берутся из . Можно отметить следующие свойства функции $\Phi \left(x\right)$.

1 . $\Phi \left(-x\right)=-\Phi \left(x\right)$, то есть функция $\Phi \left(x\right)$ является нечетной.
2 . $\Phi \left(x\right)$ - монотонно возрастающая функция.
3 . ${\mathop{lim}_{x\to +\infty } \Phi \left(x\right)\ }=0,5$, ${\mathop{lim}_{x\to -\infty } \Phi \left(x\right)\ }=-0,5$.
Для вычисления значений функции $\Phi \left(x\right)$ можно также воспользоваться мастером функция $f_x$ пакета Excel: $\Phi \left(x\right)=НОРМРАСП\left(x;0;1;1\right)-0,5$. Например, вычислим значений функции $\Phi \left(x\right)$ при $x=2$.

Вероятность попадания нормально распределенной случайной величины $X\in N\left(a;\ {\sigma }^2\right)$ в интервал, симметричный относительно математического ожидания $a$, может быть вычислена по формуле
$$P\left(\left|X-a\right| < \delta \right)=2\Phi \left({{\delta }\over {\sigma }}\right).$$
Правило трех сигм . Практически достоверно, что нормально распределенная случайная величина $X$ попадет в интервал $\left(a-3\sigma ;a+3\sigma \right)$.
Пример 1 . Случайная величина $X$ подчинена нормальному закону распределения вероятностей с параметрами $a=2,\ \sigma =3$. Найти вероятность попадания $X$ в интервал $\left(0,5;1\right)$ и вероятность выполнения неравенства $\left|X-a\right| < 0,2$.
Используя формулу
$$P\left(\alpha < X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right),$$
находим $P\left(0,5;1\right)=\Phi \left({{1-2}\over {3}}\right)-\Phi \left({{0,5-2}\over {3}}\right)=\Phi \left(-0,33\right)-\Phi \left(-0,5\right)=\Phi \left(0,5\right)-\Phi \left(0,33\right)=0,191-0,129=0,062$.
$$P\left(\left|X-a\right| < 0,2\right)=2\Phi \left({{\delta }\over {\sigma }}\right)=2\Phi \left({{0,2}\over {3}}\right)=2\Phi \left(0,07\right)=2\cdot 0,028=0,056.$$
Пример 2 . Предположим, что в течение года цена на акции некоторой компании есть случайная величина, распределенная по нормальному закону с математическим ожиданием, равным 50 условным денежным единицам, и стандартным отклонением, равным 10. Чему равна вероятность того, что в случайно выбранный день обсуждаемого периода цена за акцию будет:
а) более 70 условных денежных единиц?
б) ниже 50 за акцию?
в) между 45 и 58 условными денежными единицами за акцию?
Пусть случайная величина $X$ - цена на акции некоторой компании. По условию $X$ подчинена нормальному закону распределению с параметрами $a=50$ - математическое ожидание, $\sigma =10$ - стандартное отклонение. Вероятность $P\left(\alpha < X < \beta \right)$ попадания $X$ в интервал $\left(\alpha ,\ \beta \right)$ будем находить по формуле:
$$P\left(\alpha < X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right).$$
$$а)\ P\left(X>70\right)=\Phi \left({{\infty -50}\over {10}}\right)-\Phi \left({{70-50}\over {10}}\right)=0,5-\Phi \left(2\right)=0,5-0,4772=0,0228.$$
$$б)\ P\left(X < 50\right)=\Phi \left({{50-50}\over {10}}\right)-\Phi \left({{-\infty -50}\over {10}}\right)=\Phi \left(0\right)+0,5=0+0,5=0,5.$$
$$в)\ P\left(45 < X < 58\right)=\Phi \left({{58-50}\over {10}}\right)-\Phi \left({{45-50}\over {10}}\right)=\Phi \left(0,8\right)-\Phi \left(-0,5\right)=\Phi \left(0,8\right)+\Phi \left(0,5\right)=$$